
Deepseek: How US accidentally Made China Great Again
And why we really don't need another Cold War


“Deepseek will end US dominance.” “Deepseek is a Chinese weapon, stealing data for the government.” “Deepseek achieved for $5 million what OpenAI did with billions.” “Deepseek is censored and avoids discussing Tiananmen Square.” “Deepseek is a ChatGPT killer.” Deepseek this, Deepseek that…
For the last two weeks, I’ve been trying to understand what’s going on with Deepseek and why I should even care, but the sheer amount of conflicting opinions and sensationalist headlines overwhelmed me. So I decided to stop reading the news for a few days and just use the model. I have to say, it was really enjoyable.
After reading about it and testing it out for a while, I’ve finally come to the conclusion that this model’s release is incredibly important—not just because of the innovation, but also because it revealed some things about the state of the AI industry that not too many people are going to like…
What is it and who made it?
DeepSeek is a Chinese artificial intelligence lab that has published a couple of excellent models. The most notable one, which made all the headlines, is called Deepseek R1. This is a reasoning model similar to OpenAI’s o1, which was known as “the most advanced” AI model at the beginning of 2023. Both models perform similarly well on benchmarks thanks to their ability to “think” before answering. They produce a long internal chain of thought to break down problems.
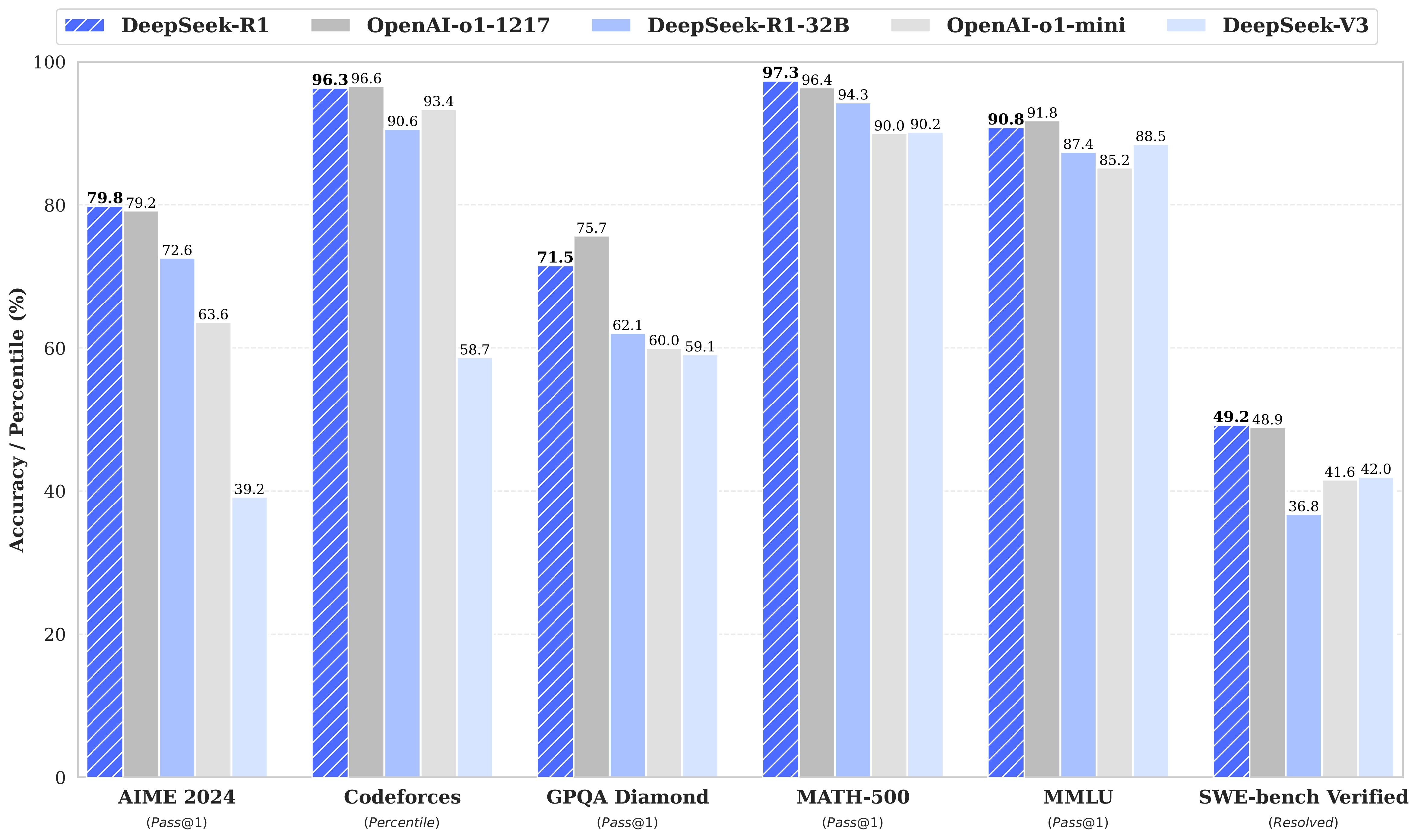
While you can’t see OpenAI o1’s internal dialogue, Deepseek’s dialogue is fully visible to the user—and oh, what a joy it is to see its internal thoughts. It’s not just thoughts that are openly visible. Unlike OpenAI’s models, where we don’t know how much they cost, how many parameters they have, how they were trained, or what type of architecture they use, we pretty much know all of that for Deepseek R1.
Now, this has to be one of the greatest ironies I’ve ever seen in my life. A model developed in China—famous for its totalitarian regime and lack of transparency and democracy—is open, while the other model, from the US (which supposedly champions freedom and openness), is closed?
Thanks to researchers at Deepseek, who published their models as open source (under the MIT license), you can download them and use them (for free) on your own computer if it’s powerful enough. If you’re like most of us and can’t run this model from home—but also don’t want to share your chat history with the Chinese government—you can find Deepseek hosted on many US servers. For example, Perplexity hosts the model.
Now back to Deepseek. The two most significant models they’ve released are:
Deepseek V3 → a pretrained model with MoE (Mixture of Experts) architecture and a total of 671 billion parameters. This is the model that “threatens US dominance,” since its performance either surpasses or is on par with American models—while being significantly cheaper to train.
The above-mentioned and most popular R1 model, built on top of Deepseek V3 with an additional step called Group Relative Policy Optimization or GRPO. It’s a Reinforcement Learning step that leads to chain-of-thought problem-solving.
So how “cheaper” are these models compared to American ones?
Deepseek is a side project that cost 5 million dollars?
Donald Trump is in a blue suit and a bright red tie with a small American flag on his left shoulder. He looks a bit less energetic than usual as he announces “the largest AI infrastructure project in history” and says “it’s all taking place right here in America.” He’s talking about Stargate, a $500 billion investment into AI development that’s already taking root in Texas.

This news shows that the US government is serious about leading the AI revolution. But it also hints at something AI leaders have been saying for a while: Hundreds of billions of dollars are NECESSARY to train better models than the ones we have right now.
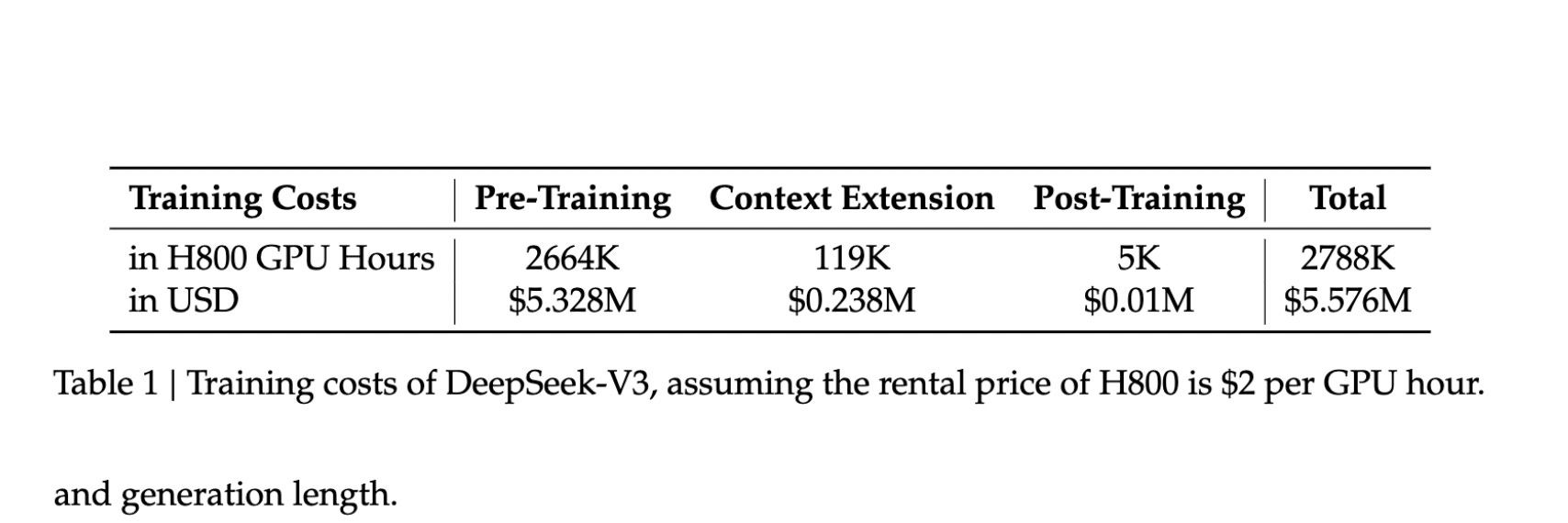
Which is why the news that Deepseek trained its V3 model for “only” $5.5 million felt like a slap in the face for US companies. For comparison, although it was never revealed how much OpenAI paid to train GPT-4o model, Dario Amodei of Anthropic confirmed that Claude 3.5 Sonnet cost “a few $10M’s” to train. Meta also never disclosed the price of their SOTA model Llama 3.1, but according to one estimate, training it was likely in the range of $90–120 million.
An interesting rumor circulated on social media: allegedly, Deepseek was a side project started by hedge fund CEO Liang Wenfeng. It would be pretty cool if a team of developers just casually, as a side quest in their free time, created a frontier model. But that’s not entirely true. Deepseek was indeed founded by Liang Wenfeng, who has a background in Information and Communication Engineering. After working on trading algorithms for a decade, he started Deepseek in 2023 with the mission of reaching AGI. Their hiring strategy mostly focused on motivated recent graduates with diverse backgrounds.
So how did such a young, relatively small team pull off the most efficient model training ever seen, far before any giants with much larger budgets like Google or Meta?

Did the U.S. Accidentally Give China a Big Boost in AI?
You might have seen this phrase on social media: “The USA Innovates, China Replicates, and Europe Regulates.” I think it reflects a long-held belief that China just creates “copycats.” In the West—or at least in Silicon Valley—copying an idea is stigmatized, but Chinese entrepreneurs in the early to mid 2010s didn’t seem to care. Take Wang Xing, a Chinese businessman who literally and shamelessly cloned Facebook, Twitter, and Groupon. Well, he is now a billionaire.
Even though many Americans might “look down” on Chinese tech, the U.S. government sees it more as a threat. In an effort to maintain America’s AI dominance and limit China’s potential military growth, the Biden administration imposed “export controls.” Put simply, sending advanced U.S. tech—like GPUs or certain software—to China is banned. This should make it harder for them to train and run AI models, since their domestic GPUs are lagging. Nvidia did create the H800, a weaker GPU for the Chinese market, but the Biden administration banned it in 2023. Finally, Nvidia began developing an even less powerful chip, the B20, which is allowed for export.
It appears Deepseek purchased at least 2,048 Nvidia H800 GPUs in 2023 to train its V3 model. At the time, these chips were still legally available because the U.S. restrictions on the H800 only came into effect in October 2023.
So Deepseek had less powerful chips than American companies, yet still managed to train such a great model—how? It looks like they made some nice engineering breakthroughs:
MoE (Mixture of Experts) architecture → Technically they didn’t invent this type of architecture, but their implementation pushed the boundaries of efficiency. Only 37 billion parameters out of 671 billion are active at once.
Multi-Head Latent Attention → This boosts efficiency by letting the model process multiple aspects of input data at the same time.
Multi-Token Prediction → Unlike models that predict one token at a time, DeepSeek’s models predict multiple tokens simultaneously, speeding up training and improving accuracy.
It’s hard not to think that Deepseek’s team—working with less powerful hardware yet aiming for AGI—felt a lot of pressure, which led them to innovate. It’s also impossible not to notice that China is moving toward self-reliance. As a response to U.S. sanctions, China plans to replace foreign tech in state systems by 2027. So not only are U.S. sanctions failing to stop Chinese companies from building top-tier AI models, but they’re also fueling growth in China’s hardware industry and scientific innovation.
Does it really make sense to keep insisting on these export controls?

All humanity will benefit from AGI (but some will benefit more than the others)
CEO of Anthropic, Dario Amodei, has a reputation as a “good” CEO. He’s far less in the spotlight than Sam Altman, and his company’s cautious approach to releasing models signals that they take safety seriously. In one of his popular blog posts, he talks about how AI might help eliminate cancer, mental illnesses, and raise countries out of poverty. Considering he’s one of the leaders racing to reach AGI, it’s reassuring to know he cares about humanity and wants to reduce suffering.
But here’s where things get ugly. After Deepseek’s release, Dario published another blog post where he doubles down on the idea that the world is split into a democratic bloc (presumably led by the U.S.) and an authoritarian bloc (presumably led by China). According to him, democratic countries must establish and maintain a one-sided world where they hold all the power. They also need to do everything they can to stop China from developing AGI.
Whether it’s better to live under a unilateral world order like we did for the past 30–40 years (the “Pax Americana” period), or under a bilateral or multilateral world, is up for debate. I won’t get into that here. But if AGI really can “benefit all humanity” by curing diseases and lifting people from poverty, that suggests Dario believes Chinese researchers shouldn’t get to achieve these goals—at least not if it risks the U.S. losing its lead. He does say: “the goal here is not to deny China or any other authoritarian country the immense benefits in science, medicine, quality of life, etc. that come from very powerful AI systems. Everyone should be able to benefit from AI. The goal is to prevent them from gaining military dominance.” However, that seems impossible. If an AI model is smart enough to cure stage IV cancers, it’s likely smart enough to bring major military advantages.
Meanwhile, Deepseek’s researchers are sharing their models and breakthroughs openly, while CEOs of Western companies defend their secrecy and back U.S. sanctions on China. You can’t help but wonder: when American CEOs say “all humanity should benefit from AGI,” do they by “humanity” really just mean Americans and their military allies?

Competitors, Not Enemies
There are two things I can learn from Deepseek’s story:
China’s progress in AI is hard to stop.
Another “Cold War” might be good for a handful of company leaders but will likely be bad for everyone else.
Let’s begin with China’s AI progress. Kai-Fu Lee is a famous computer scientist and the founder of 01-AI Lab, which released a series of Yi models. In his book AI Superpowers, Lee explains that AI progress can be divided into two periods: the age of “discovery” and the age of “implementation”. According to him, “during the discovery phase, progress was driven by a handful of elite thinkers, virtually all of them in the United States and Canada.”1 But this phase—responsible for breakthroughs like transfer and reinforcement learning—is slowing down as we move into the implementation phase. And this transition “tilts the playing field toward China”.2 While China may not have as many elite researchers, it has plenty of “scrappy entrepreneurs” and mountains of data.
Deepseek’s story seems to prove Lee’s point. A startup founded by an entrepreneur with no machine learning background “takes” engineering discoveries from the West (like the MoE architecture) and makes huge progress by refining them. Along with China’s goal of replacing all Western hardware by 2027, I don’t see how their AI progress could be slowed down.
Given China’s rapid rise, it’s easy to see why many compare this era to the mid-20th century, when the Soviets and the Americans competed over who gets to conquer space first. But to quote Lee again: “Our current AI boom shares far more with the dawn of the Industrial Revolution or the invention of electricity than with the Cold War race.”3 I hope he’s right. At the dawn of the Industrial Revolution, entrepreneurs fought over who gets to build the best steam engine or longest railway. If today’s “War” is similar to Industrial Era and if it remains a contest between AI companies building the best chatbots or image generators, that’s great. Healthy competition will give us all better AI products. But things can take a darker turn.
If this “War” means depriving brilliant researchers of the tools they need to cure stage IV cancer—just because developers on the other side of the globe need to be first to secure a dominant position for their government—then personal interests are prioritized over the collective good.
Ultimately, both working-class Americans and Chinese people share a common and possibly bigger threat: mass unemployment caused by AI, which could happen sooner or later. Nobody really knows how to handle unemployment on such a huge scale, and since our economies are interdependent, the governments of major superpowers should collaborate on this issue. It certainly wouldn’t be the first time opposing blocs have worked together. The International Space Station and successful cancer clinical trials both resulted from collaborations among researchers around the world—especially from the U.S., China, and Russia. I think it’s best to leave the competition for best AI products to private companies while demanding open, global research on truly painful problems like illnesses and poverty.
Kai-Fu Lee, AI Superpowers (Boston: HarperCollins Publishers, 2018), 13
Lee, AI Superpowers, 15
Lee, AI Superpowers, 228